
読了時間:15分
皆さん、こんにちは!
今回の初学者チュートリアルは、データクレンジングで必ず使うことになるpythonのモジュール「Pandas」に焦点を当てます。とはいっても、Pandasは非常に使いやすくポピュラーなモジュールですので、既にたくさんのまとめサイトがあります。この記事ではそれらをどんどん紹介していきたいと思います。
一般的なPandasの使い方
一般的な使い方については、こちらにまとめられておりますので、参照して下さい。
以下、特によく使う方法をピックアップします。
Pickup1:データの結合
データクレンジングでは必ずと言っていいほど、データの結合を行います。とくに、以下の3つの方法をよく使います。
- pd.concat(コンカット、インデックスやカラム名での連結に使う)
- pd.merge(マージ、特定のカラムのデータをキーとして連結する)
- pd.append(アペンド、おもに縦方向の連結に用いる)
これについては既にこちらやこちらによくまとまっていますので、参照いただければと思います。
Pickup2:データ抽出
データクレンジングの場面では、
「このデータのこの部分だけ取り出したい…!!」
というケースがあると思います。これについてはこちらやこちらに載っております。とくに、Pandasではインデックスでいかにデータを高速処理するかが勝負どころですので、ぜひ参照して下さい。
Pickup3:読み込み開始行の指定
皆さんは、下画像のような場面に出くわしていませんか?CSVファイルの冒頭部にデータ説明の記述があり、処理において途中の行から読み込みたいことはありませんか?
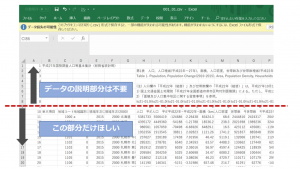
このようなときは、read_csv時に引数「skiprows」を指定してください。詳細はこちらにありますので参考にして下さい。
書籍の紹介
今回紹介したような様々なデータ処理方法は、
に載ってあります(ラボにも用意してありますので、購入の必要はありません)。SQL/R/Pythonをふくめた手法を学ぶことができますので参考にしてください。

いかがでしたか?データ処理は早めに覚えて、ルーティンワークにしてしまいましょう!!
執筆者:宮本